NTSYS-PC(Numerical Taxonomy and Multivariate Analysis System)是一款广泛应用于生物学、生态学及遗传学领域的数值分类与多元分析软件,尤其适用于分子标记数据的聚类分析和遗传相似度计算。本文详细介绍了利用NTSYS-PC进行数据矩阵构建、系统树生成及遗传相似度表导出的完整流程,适用于AFLP、RAPD、SSR等分子标记数据的分析。
1. 数据矩阵构建
在Excel中按以下规则输入数据:A1单元格输入“1”(表示有带记为1),B1输入“13”(扩增总条带数),C1输入“7”(样本数),D1输入“0”(无带记为0)。第二行输入样本名称,从第三行开始,A列输入引物名称。示例如下图:
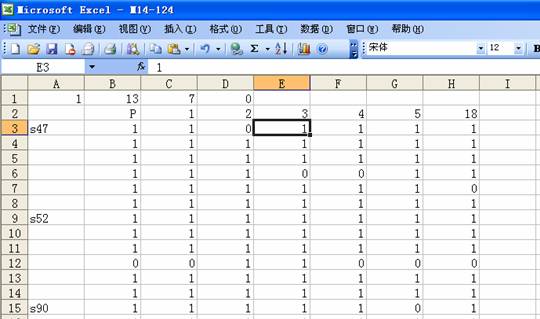
输入完成后,将文件另存为“Microsoft Excel 5.0/95工作簿”格式(.xls)。
2. 系统树(聚类图)生成
打开NTSYS-PC程序,依次点击:
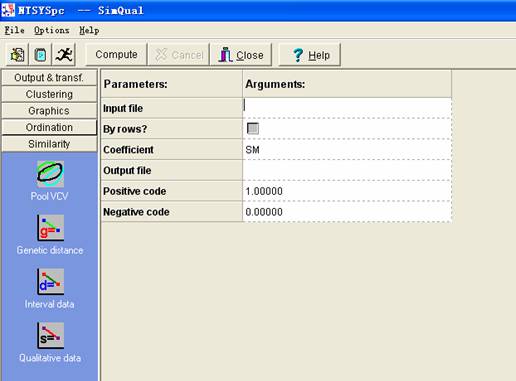
(1)Similarity → 出现界面后,点击Qualitative data,弹出对话框。
(2)在对话框中,点击Input file,选择之前保存的Excel文件;点击Out file,输入输出文件名(例如“A”);然后点击Compute按钮,计算相似性矩阵。
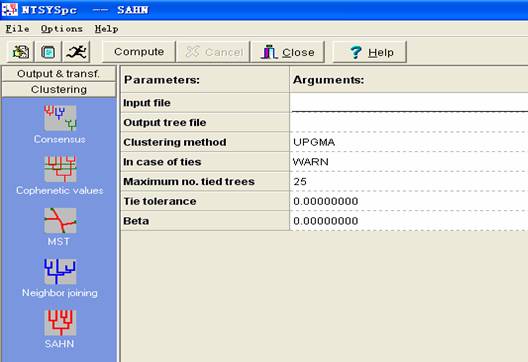
(3)点击Clustering,出现聚类分析界面。
(4)点击SHAN(层次聚类),在弹出窗口中:点击Input file,选择上一步生成的文件“A”;点击Out file,输入输出文件名(例如“B”);点击Compute按钮,生成聚类结果。
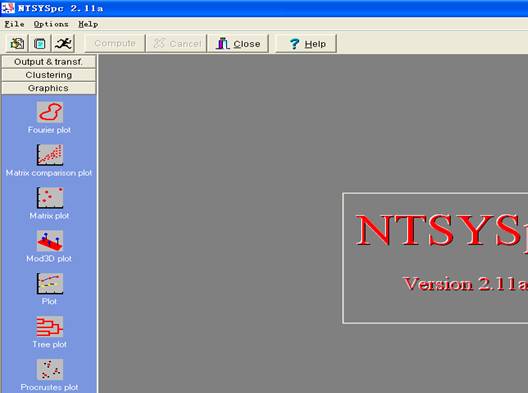
(5)点击Graphics → Tree plot,在界面中:点击Input file,选择文件“B”;点击Compute按钮,即可显示聚类树状图。
3. 遗传相似度表生成
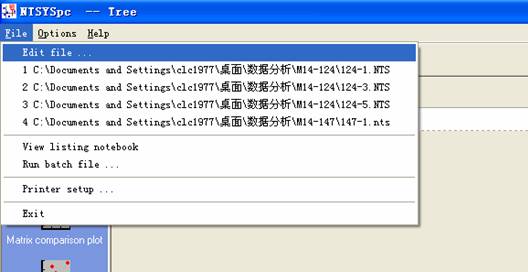
点击File → Edit file,打开之前生成的文件“A”;然后点击Compute按钮,即可得到遗传相似度矩阵表。
NTSYS-PC功能强大,除聚类分析和遗传相似度计算外,还支持主成分分析(PCA)、多维标度分析(MDS)等多元统计方法。用户可根据研究需要进一步探索其他功能。如有疑问,欢迎交流讨论。